
VoidPapers: Accrual Failure Detectors

Reading
-The φ accrual failure detector
-Hayashibara, Naohiro; Defago, Xavier; Yared, Rami; Katayama, Takuya
-Research report (School of Information Science, Japan Advanced Institute of Science and Technology), IS-RR-2004-010: 1-15
-http://hdl.handle.net/10119/4784
I had a lot of fun reading this paper! It introduces an implementation for a new type of failure detector that expresses the degree of suspicion of a distributed system on a continuous scale rather than the conventional boolean trust vs suspect method. The authors evaluated the experimental failure detection implementation scheme by sending UDP heartbeat messages on a transcontinental link between Japan and Switzerland. They gathered a total of about six million samples.
Fault tolerance is a key characteristic of distributed systems. Distributed systems need to keep functioning normally [being reliable and highly available] in the event of a failure in one of its components. Failure detectors play an important role in ensuring fault tolerance in distributed systems. Given how fundamental failure detection is to ensuring the fault-tolerance in distributed systems, the paper highlights the demand for a failure-detection as a service product. Unfortunately, such a service cannot be done using classical failure detectors. Since services vary in their quality of service requirements a classical failure detector with a one-size-fits-all trust vs suspect interaction is not dynamic enough to be offered as a software service. Varying services running simultaneously need to be able to tune their failure detectors to cater to their specific use cases & quality of service requirements.
Existing failure detectors are based on a boolean interaction — suspect or trust, The Accrual Failure Detector introduced in this paper outputs values on a continuous scale, these values can be thought of as the degree of confidence that a system being monitored has crashed. Roughly speaking, the higher the value, the higher the chance that the monitored process has crashed. These values accrue based on the accuracy of past results. Each service sets a suspicion threshold based on its own quality of service requirements. A concept introduced early on in the paper that is quite fundamental when thinking about the implementation of failure detectors is the tradeoff that often exists between the detection time frame for a failure detector and the accuracy of the detector.
To further explain the Accrual Failure Detector, the authors gave a really great example, I’ll try to reword it — assume we have a distributed application with a master process whose duty is to hold a list of jobs to be run and designate these jobs to other [worker]processes. It is important for the master process to detect any worker process crashes and take necessary action to prevent the system from blocking. An Accrual Failure Detector will flag a worker when it reaches a low degree of confidence & the master will stop sending new jobs to the worker. After further monitoring, if the accrual failure detector’s degree of confidence in that worker reaches a moderate level, it will cancel all unfinished jobs and resubmit them to a new worker which isn’t flagged. The authors define an accrual failure detector as a failure detector that outputs a value associated with each of the monitored processes, instead of a set of suspected processes.
The phi failure detector is an adaptive implementation of the accrual failure detector, it samples a window of heartbeats[1] and maintains a sliding window of the most recent sample which is then used to estimate the arrival time of the next heartbeat, similarly to conventional adaptive failure detectors.
Next up, The authors explore various implementations of failure detectors and some basic concepts. I’ll summarise very briefly below.
Unreliable Failure Detectors
This is a failure detector oracle that can make mistakes in detecting failure to a certain degree of correctness. This failure detector can make mistakes in detecting failures in processes. It may not suspect a crashed process or suspect a correct one.
Quality of service of failure detectors
As discussed above, various distributed applications have varying failure detector needs based on their quality of service metrics. The paper cites Chen et al. [10] and describes their proposition for quality of service metrics. The Detection time(T) is the time that elapses since the crash of p and until q begins to suspect p permanently where p & q are the only two processes on the system and process q monitors process p.
The second proposed quality of service metric is the Average mistake rate (λM) which is a measure of the rate at which a failure detector generates wrong suspicions.
Heartbeat failure detectors
In this section, we briefly discuss heartbeat failure detectors as described in the paper. A basic understanding of heartbeats in the context of distributed systems will be helpful, The Martin Fowler blog has a great piece here.
In discussing the heartbeat failure detectors, we still retain our hypothetical system with only two processes p & q from above. The monitored process(p) periodically sends heartbeat signals to process q in a period called the heartbeat interval. Process q begins to suspect process p if it fails to receive a heartbeat message from p in the timeout period which is typically greater than or equal to the heartbeat interval. As we have seen above If the timeout period is short, crashes are detected quickly but there is a higher chance of a wrong suspicion being outputted. Conversely, if the timeout is long, wrong suspicions become less frequent, but this comes at the expense of detection time.
Adaptive failure detectors
We have already discussed adaptive failure detectors above but I would like to highlight something I found interesting from the paper. For traditional timeout-based failure detectors, monitoring of processes for failure and interpretation of the results are coupled while their adaptive counterparts are decoupled.
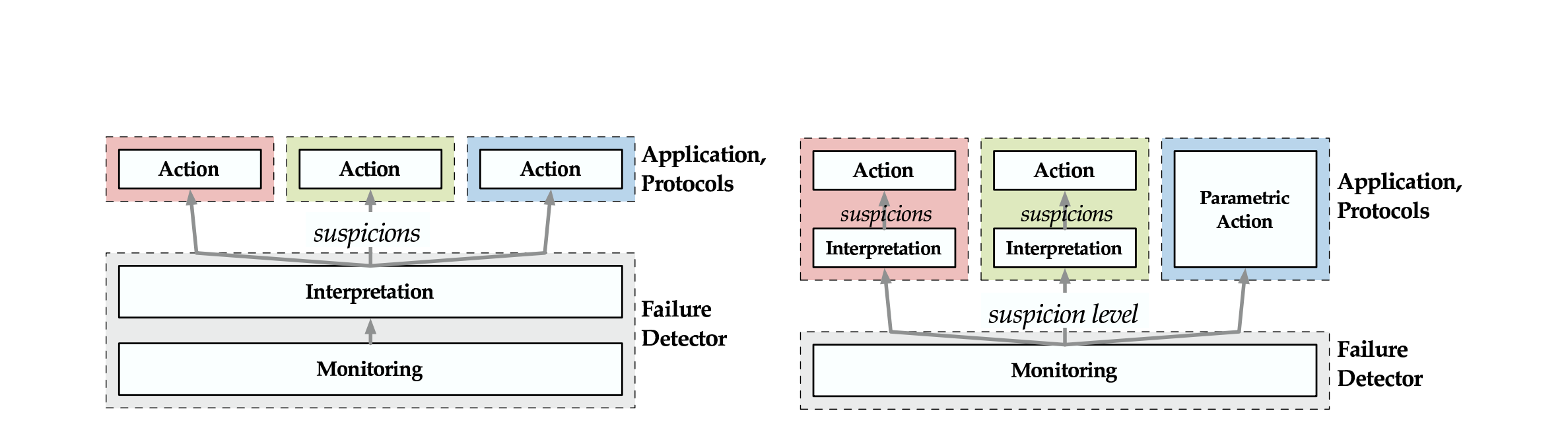
The above image shows the structure of a traditional failure detector on the left & the structure of an accrual failure detector on the right.
The paper also describes some other network-based failure detector implementations — Chen & Bertier failure detectors.
Real Life Applications Of the Accrual Failure Detector
While reading this paper, I searched around and found a couple of interesting applications of the accrual failure detector in “real world” software. Some notable implementations are highlighted below.
Every node in Cassandara, the row store, runs a variation of the phi Accrual failure detector. Check out the source here.
Azure Service Fabric which is a distributed systems platform
A simple implementation of a failure detector in Golang by dgryski(Github)
Further Reading
Here are links to some papers similar to this I came across while learning more about Failure detectors.
Implementation and performance evaluation of an adaptable failure detector by Marin Bertier, Olivier Marin, Pierre Sens
On the quality of service of failure detectors by Wei Chen, Sam Toueg, Marcos Aguilera
I hope you enjoyed reading this week’s VoidPaper! Remember to subscribe to get the latest issues in your inbox every week.